
- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-


Pyramid provides the fastest analytic solution for SAP HANA using SQL while still exposing all its deep analytic logic and functionality. When combined with Pyramid’s complete self-service analytics platform, it’s one of the strongest and most comprehensive analytical toolsets for SAP HANA in the market.
In this two-part series, we’ll explore Pyramid’s key functional capabilities and certifications for SAP HANA.
One of the key challenges in the marketplace for SAP customers is to find a great set of tools that work directly on SAP HANA technologies with modern self-service analytic capabilities—while exposing all the enterprise, server-based functionality required for security and governance. Few companies want to lose this functionality when implementing a BI tool with their HANA engine or be forced to extract the data into some proprietary data layer.
In short, customers want “Real self-service BI that works directly on SAP HANA.”
HANA is a super-fast, in-memory, relational database that acts as both the storage destination for SAP’s ERP—S4HANA—as well as a generic database solution that enables data analysts to query large data volumes in real-time.
Importantly, HANA has its own deep analytics capabilities deployed through “Calculation Views,” which are designed to expose powerful business logic and analytical layer that goes well beyond a simple database.
SAP customers have some challenges today in closing the functionality gap in client analytic tools. They need to choose either from SAP’s own technologies or look to third parties. SAP’s natively integrated applications include Business Objects, Lumira, and SAP Analytics Cloud (SAC). However, each offering has limitations:
On the other hand, third-party self-service BI tools (e.g., Qlik, Power BI, Tableau, MicroStrategy) generally lack deep integration with HANA because their query engines are not built to support all the core functionality of HANA’s analytic functions. As such, they all tend to encourage users to export their raw data out of SAP and reimport it into their native data stacks to gain better analytical functionality.
The duplication of data runs contrary to the entire concept of using HANA in the first place: it compromises data governance and security; duplicates the data and analytic layers; decentralizes the “truth,” and ultimately deleverages the investments in HANA—and even SAP ERP itself. This is a very expensive price to pay for self-service capabilities—and it is the reason why many SAP customers have not found a reasonable solution to their problem.
Simply put, the challenge is to find a mature, fully functional self-service technology that offers “direct query” and full functionality on HANA without compromise—thereby fully leveraging the technologies without replacing them.
HANA offers two consumption models: the MDX route, where things like hierarchical structures are catered for at the cost of slow query times and a lack of full functional support, or the SQL route, which offers fast query times, but usually lacks the analytical feature support. (This includes hierarchies, measure formats, and business logic.)
Pyramid chose to deliver its solution using the SQL route, providing the fastest querying solution, and accessing all the deep analytic logic and functionality of HANA. However, Pyramid was designed to match the capabilities of MDX via SQL—matching all the hierarchical magic of MDX without using it.
In completing the HANA BI certification, Pyramid was able to “check the boxes” for all mandatory requirements as well as all the optional “difficult to achieve” analytic features.
In this post, I will explore how Pyramid handles hierarchies, data formats (including currencies and unit conversions), and calculated attributes and measures—all crucial capabilities that underpin our SAP HANA certification. In part 2 of this blog series, I will cover hyperlinks, parameters and variables, data modeling, and other key features of HANA.
Hierarchies are natively available in MDX but not typically available in SQL due to its flattened query structure. Pyramid, however, is designed to deliver hierarchical structures using SQL and can provide full MDX-like functionality, including multi-level, drill-down hierarchies. This even extends to ragged hierarchies and parent-child hierarchies.
This means that Pyramid customers do not have to compromise on performance to take advantage of all hierarchical functionality. Other tools (like Tableau and Power BI) do not have such support in SQL, so if a HANA client wants to take the faster SQL route, all hierarchical functionalities will be unavailable, or they need to use the slower MDX-based approach.
In the following example, a customer hierarchy consisting of language, gender, and customer number has been created and is displayed with full drill-down and drill-up functionality.
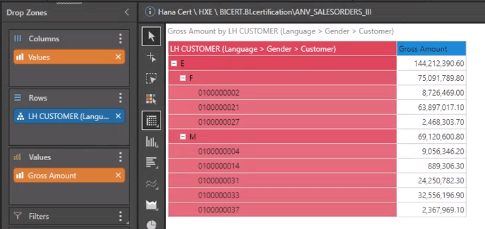
Date-Time hierarchies from HANA are also supported, as shown below, with Pyramid enabling full expansion and collapse with click-of-the-button ease.
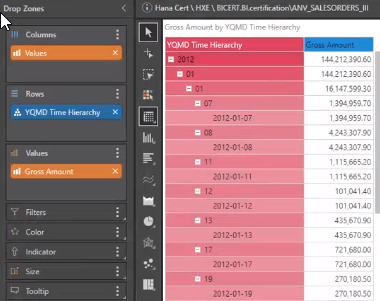
Parent-child hierarchies are commonly used in business applications, especially in financial and organizational analytics. Most tools ignore this relationship, and all crucial hierarchical reporting becomes difficult or impossible to achieve—unless they have deep support for MDX and use it as the querying interface. Pyramid caters to this capability and delivers powerful reporting with full hierarchy expansion and collapse while also catering to ragged, uneven hierarchies. What’s more, it achieves this directly on HANA without duplicating the data or structures.
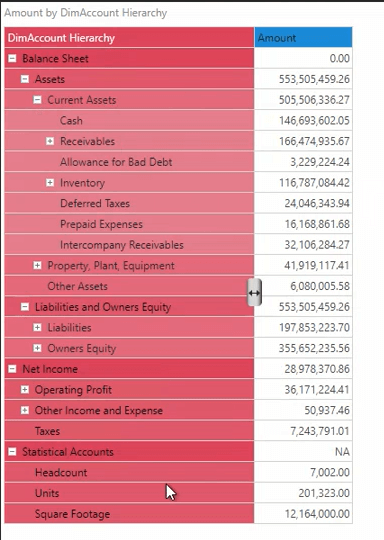
A financial SAP HANA database reflects the inherent parent-child relationship defined in the finance table. The components are defined in the model, displaying the columns used to define the parent, child, and descriptive columns. After running the model, Pyramid generates the hierarchical structure, automatically recognizing six levels present in the hierarchy and generating metadata for each of the levels in the Account hierarchy dimension. The preview of the data in the data model displays the relationship between the parent and child keys.
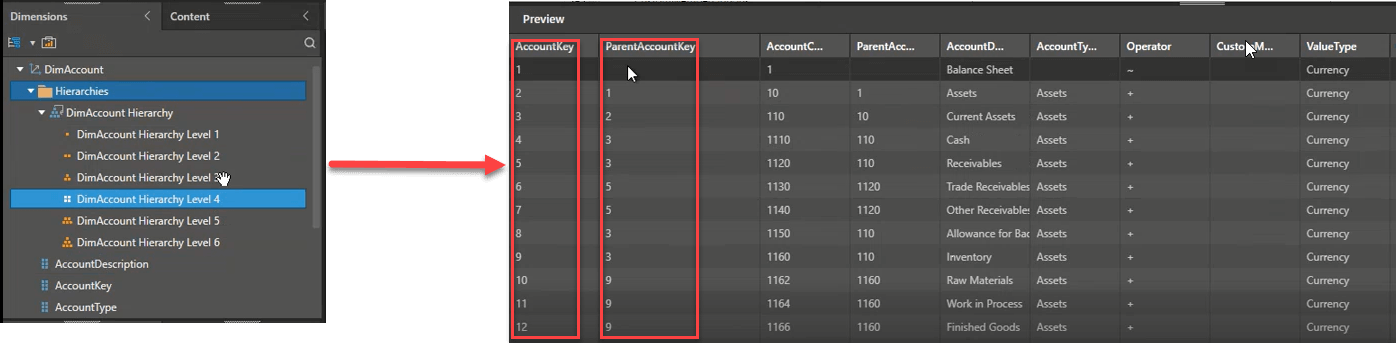
Pyramid’s hierarchical management provides effortless expansion and collapse of its ragged hierarchies. The entire balance sheet, with its implicit ragged hierarchy, is displayed, rolling up the children’s amount to the parent hierarchy.
HANA can store multiple currencies in a single column with their currency type, in addition to their converted value to a preferred currency. With many tools, data formatting is ignored, and it is displayed in an ambiguous “unformatted” way. In Pyramid, all formatting choices are reflected in the reports and visualizations as they have been configured in HANA. Importantly, any business logic that aggregates multiple currencies is properly flagged and formatted.
Customers’ sales figures appear in the model below as a gross amount with the applicable currency. The currency (which disappears in other BI tools) must be displayed, and an additional calculated column must appear where the amount is converted into Euros. Where a sum of items is not logically possible, like the aggregation of amounts with different currencies, a clear indication must be made to show that the addition is not applicable.

In this next report, the Mexican Oil and Russian Electronic Trading companies appear in a group with a sub-total without having to download the data first. The direct query in Pyramid formulates and resolves this calculation seamlessly.

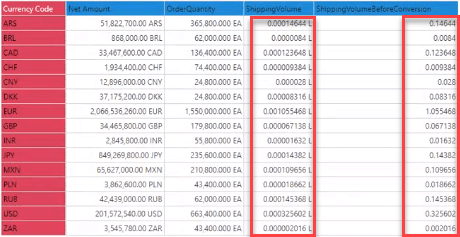
HANA can drive numeric conversions—for example, converting volume from milliliters to liters. Pyramid both recognizes and displays the converted amounts together with the units, a feat unmatched by many tools.
In this Discovery, we see HANA columns of a shipping volume before conversion as it appears in raw data (fifth column), and the shipping volume after division by a thousand in the fourth column, appended with the “L” (liter) unit.
Calculated attributes and measures
90% of all analytics require some type of calculated logic. Many users wanting to make direct queries on their existing HANA database are severely hampered when attempting to perform mathematical and set-based logic because of the complexity of driving client-defined calculations directly in HANA. Applications like Qlik, Tableau, and Power BI are unable to deliver advanced MDX or SQL queries directly on most data sources, including HANA. As such, users are often forced to extract and load the source data into their tool’s proprietary database to access the numerical operations required to craft business analysis.
Pyramid offers users deep and complete functional access to HANA to resolve the mathematical and set-based logic needed for analysis. It does it through its “PYRANA” query engine, which works directly on SAP HANA, using SQL to query with an-MDX like language called “PQL.”
All logic designed in Pyramid is executed as part of the direct querying process—without any functional or performance penalties. Additionally, the self-service function builders and editors are available via an intuitive point-and-click interface. End-users can write sophisticated calculations without needing to update or adjust the HANA models or databases.
Multiple calculations for month-to-date, quarter-to-date, and year-to-date sales were all set up on one dashboard—using a single date field as a parameter to drive the results. The calculations were made without a single line of code, running a direct query against the HANA data without having to download or manipulate any data. What is more, by dynamically modifying the data, all calculations were made seamlessly, directly on the data.
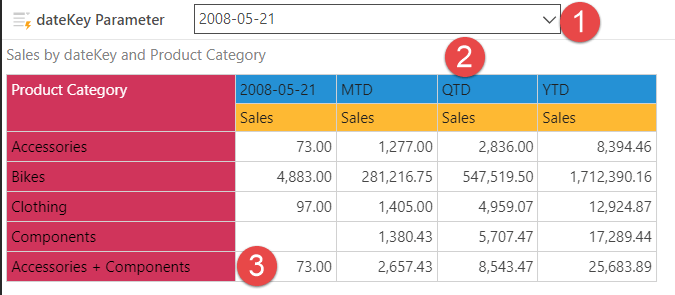
In this next example, a formula was created to calculate the month-to-date as a percentage of the year-to-date total. Pyramid’s Formulate tool allowed easy point-and-click creation of formulas with built-in wizards. In addition, for a more detailed view, the sub-category column was dropped on the dashboard. Pyramid automatically recalculated all amounts without having to reload data to a local data source. The modified query ran directly and seamlessly against the HANA data.
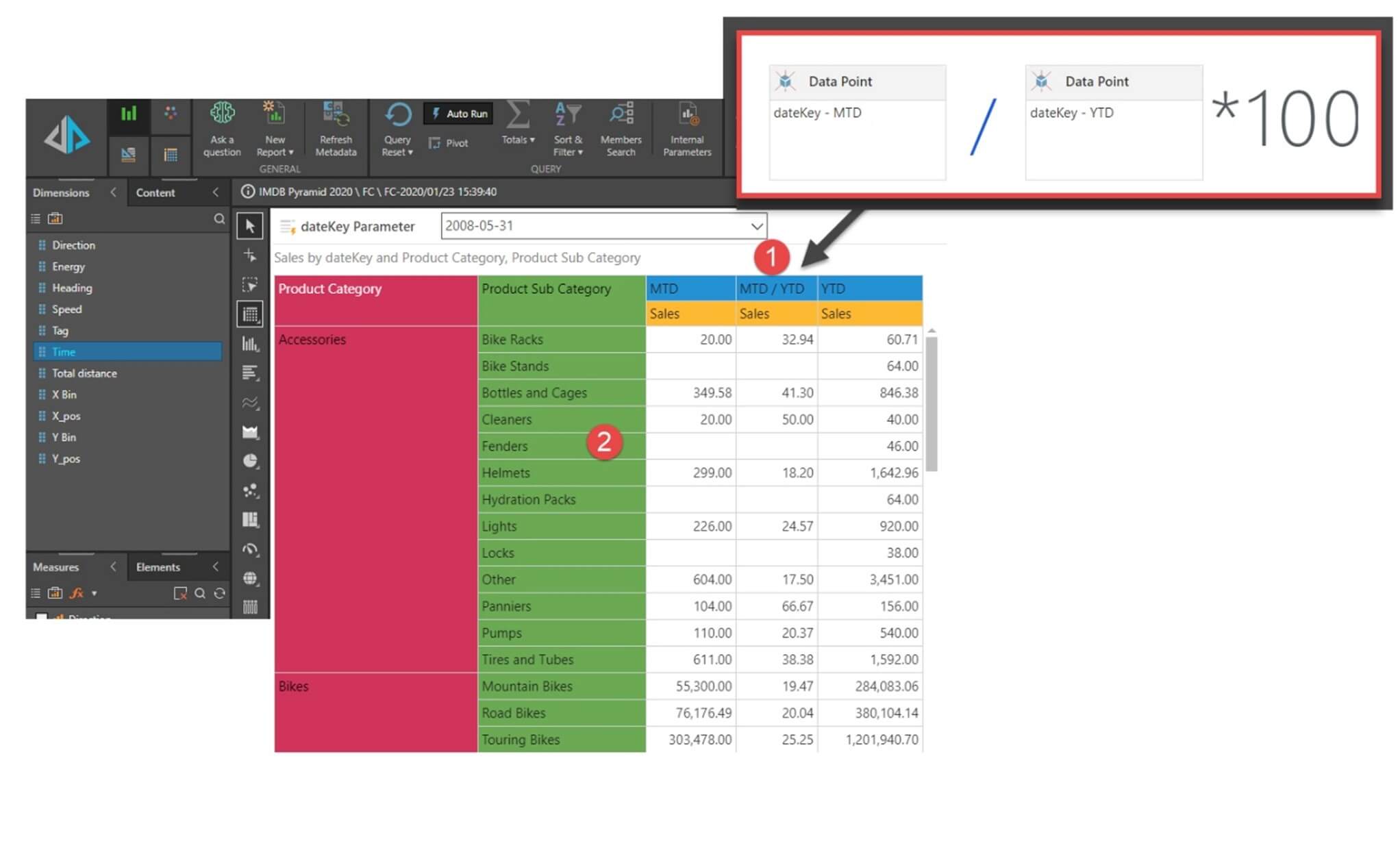
The formula to calculate the month-to-date percentage of year-to-date is created intuitively by clicking on the fields. Once the function is created, it is applied to the report or dashboard.
An additional subcategory is seamlessly added via a drop-and-drag interface. All queries are run against the original SAP database. Calculations are made by Pyramid, automatically adjusting the query to cater to the new requirements.
SAP customers need a self-service BI tool that works directly on SAP HANA, retaining all server-based functionality for business logic and governance while fully leveraging its super-fast querying performance. Further, HANA’s “Calculation Views” provide important functionality that customers do not want to lose when implementing a front-end analytics tool.
The spectrum of SAP native BI solutions currently has some limitations. Business Objects lacks self-service capabilities; Lumira has been deprecated; and SAP Analytics Cloud is immature and noticeably slow. and limited to the cloud only.
Many third-party self-service BI tools lack close integration with HANA with weak or limited support of the core functionality of HANA’s analytic functions. As such, they tend to encourage users to export their raw data out of HANA and reimport it into their native data stacks to gain better analytical functionality. The duplication of data runs contrary to the entire concept of using HANA in the first place and ultimately deleverages the investments in HANA and possibly the SAP ERP itself.
Pyramid provides the fastest querying solution using SQL while still exposing all the deep analytic logic and functionality of HANA. In doing so, it offers one of the strongest and most comprehensive analytical toolsets for SAP HANA in the market.
In the next post, we’ll take a deeper look at Pyramid’s SAP HANA features, including hyperlinks, parameters and variables, data modeling in HANA, and more.

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…