


The Pyramid decision intelligence platform
Data science is no longer just for data scientists
Pyramid’s data science workbench empowers data professionals of all kinds to build, train, apply, and deploy machine learning against data sets to discover patterns, detect anomalies, make predictions, and optimize decisions. Citizen data scientists can work in an intuitive drag-and-drop interface to apply models with guided model building, and advanced data scientists can work in their favorite coding languages, including Python or R, to build custom models.

Powerful data science
for powerful decisions
Data scientists, analysts, and non-technical end users collaborate on one application to build and deploy machine learning (ML) models. Anyone can prepare data, engineer features, build and process ML models, generate predictions, visualize results, create and launch dashboards, and consume insights to drive better business decisions, all from one platform. See our ranking in Gartner's 2024 Critical Capabilities.
Visual data science in the flow
Pyramid simplifies the ML lifecycle for both citizen data scientists and expert data scientists. In Data Flow, an intuitive visual interface that represents the data pipeline, users can drag and drop powerful AI-driven data transformations and algorithms directly in the flow or use scripting. They can leverage deep Python and R integrations to perform feature engineering, build and apply ML models, and orchestrate data pipelines. The low code or no code, automated approach helps data scientist speed up tedious tasks in a data science project.
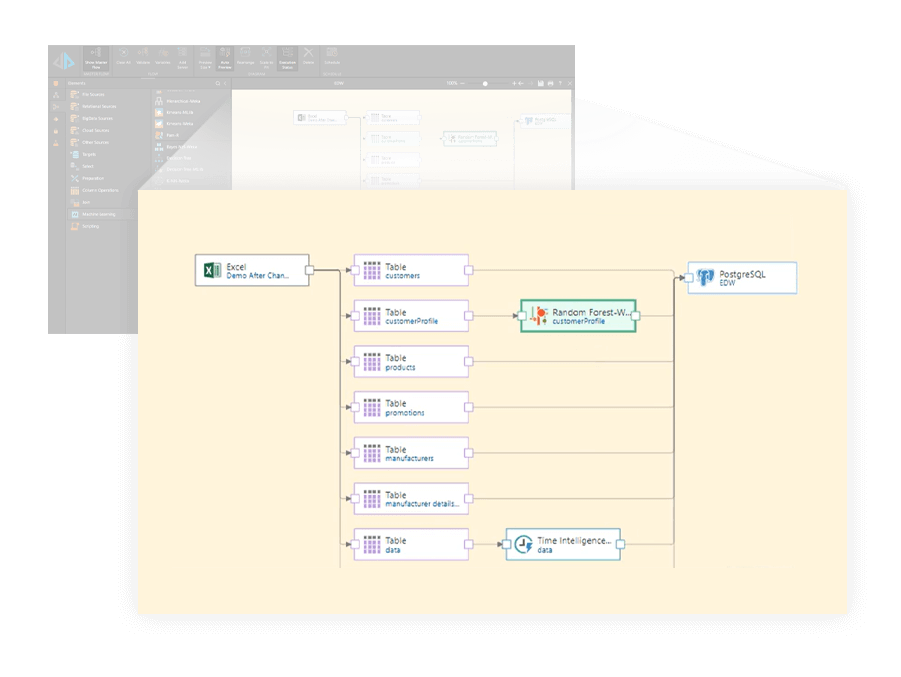
Explore, prepare, transform
Data scientists spend 80% of their time finding, cleansing, exploring, and organizing data. Pyramid’s drag-and-drop modeling tool reduces the model development lifecycle with AI-driven tools for data cleansing, wrangling, and transformations. Users can explore the shape of the input data with advanced visualizations and robust statistics for exploratory data analysis to identify dataset characteristics. They can also use natural language to generate SQL, DAX, and MDX code automatically through our ChatGPT integration.
Enable citizen data science
Pyramid provides out-of-the-box, pre-built algorithms that can easily be used by business analysts and citizen data scientists. They can apply these algorithms directly within the intuitive, drag-and-drop flow interface to perform sophisticated machine-learning tasks without any coding. Algorithms can be downloaded from the Pyramid Marketplace, selected from Pyramid’s content management system, or simply pasted into the script window.
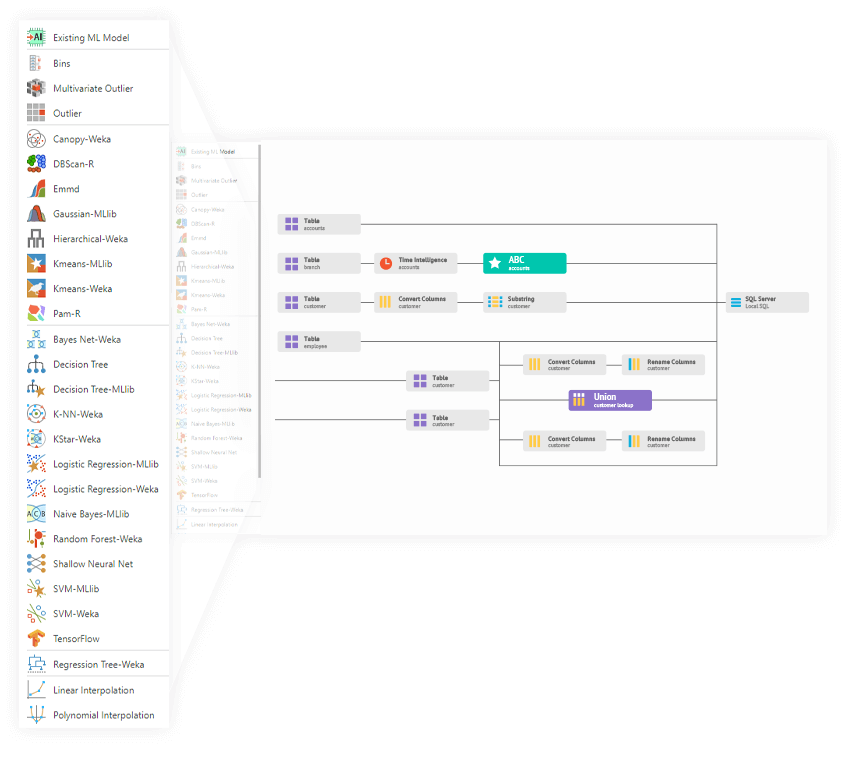
Business and decision modeling
Solve is an engine that can generate prescriptive optimization solutions based on decision models designed through the no-code or low-code spreadsheet-like Tabulate interface. Business users can build models with complex logic waterfalls, conditions, and decision points, using the entire suite of spreadsheet formulas. Solve delivers true decision intelligence on live data, answering both “What should I do” questions and “What if” simulations that can be embedded into dashboards and presentations.
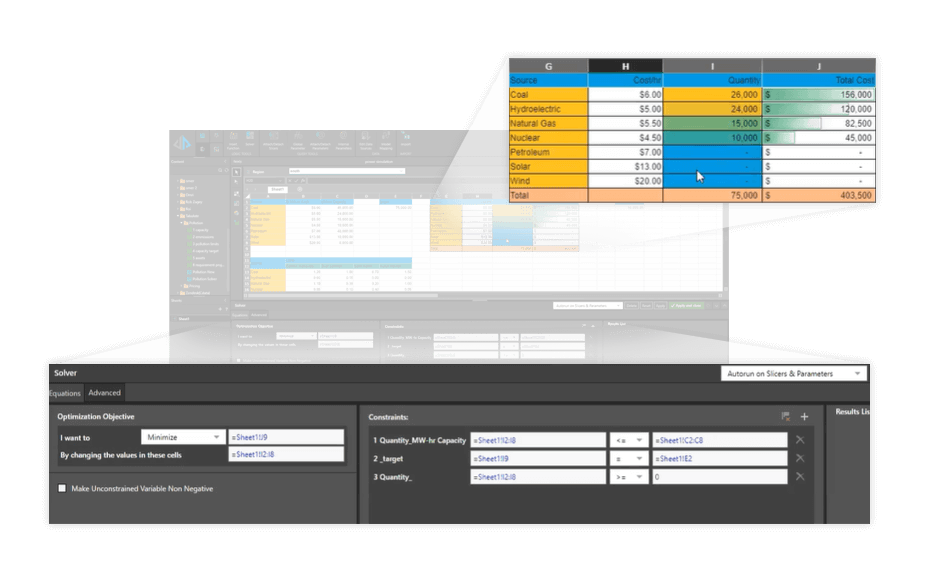
Deep Python and R integration
Pyramid has made Python and R first-class citizens in its architecture. This enables data scientists to easily train models and deploy them into production. A marketplace with free, reusable Python source code provides non-technical analysts with a library of predefined functions. And, existing Python scripts can be further customized to suit more specific business requirements.
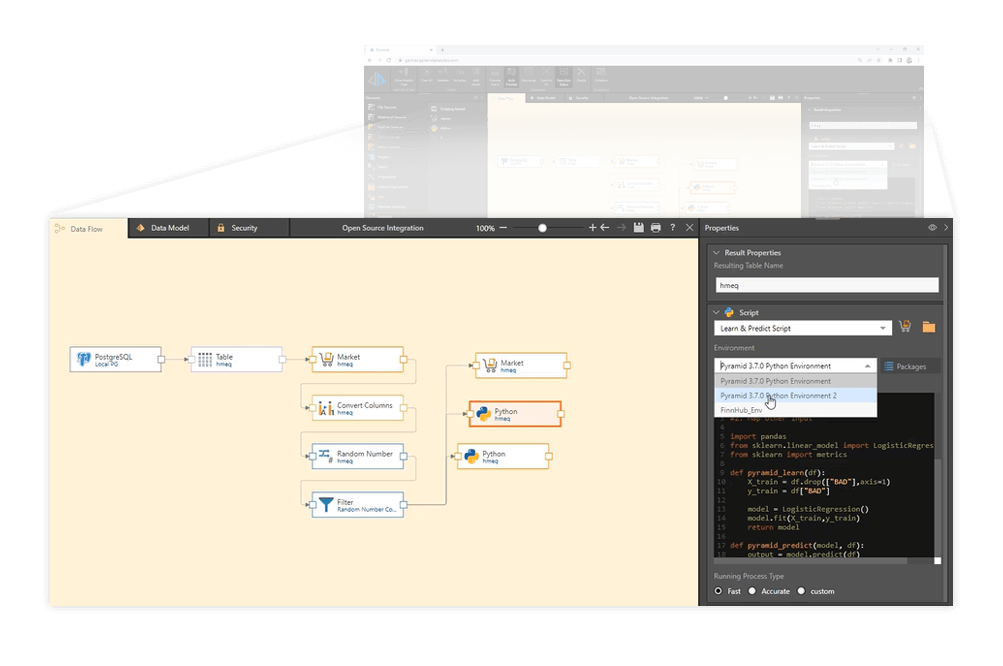
Feature engineering
Feature Engineering in Pyramid helps data scientists and business analysts transform raw data into features suitable for ML models. Apply transformations or use math functions to create new features. Access features from other platforms like Databricks that provide API access to features and share engineered features in Pyramid via rest APIs for use in other applications as well.
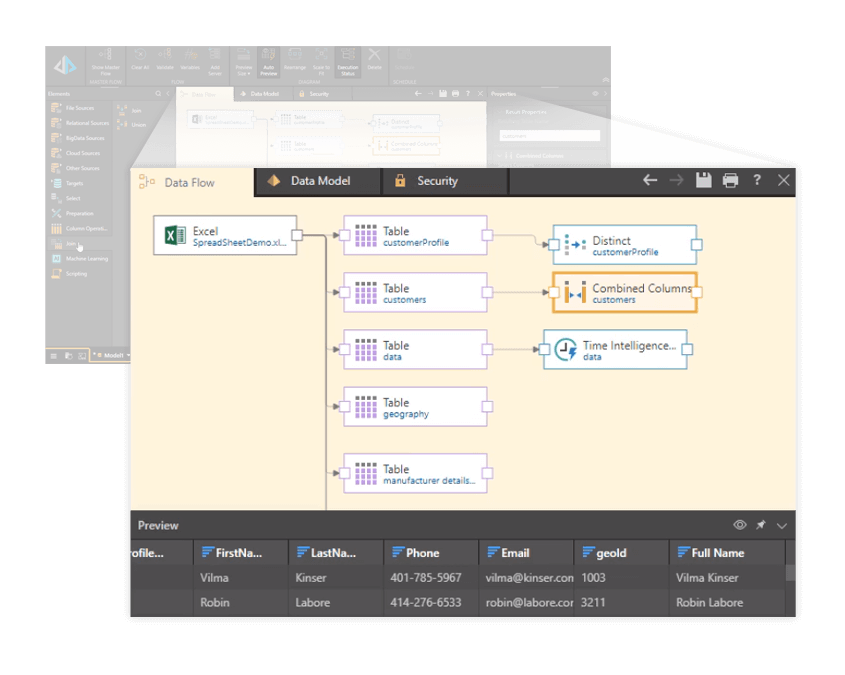
Apply, build, and train ML models
Build and train models using learn and predict scripts or regular scripts. Users can run the Learn function against training data (input) and return the ML model (output). Users have access to an extensive library of scripts, accessible through simple point-and-click prompts, including Weka, MLIB, and TensorFlow—as well as DL4J for deep learning. Pyramid features pre-built scripts to build and train models. Users can train models with various approaches to achieve faster results and higher accuracy. Alternatively, Models can be saved and re-used against other data sets and use cases. Apply your saved model to new data for testing or scoring by simply connecting it to the new data flow.
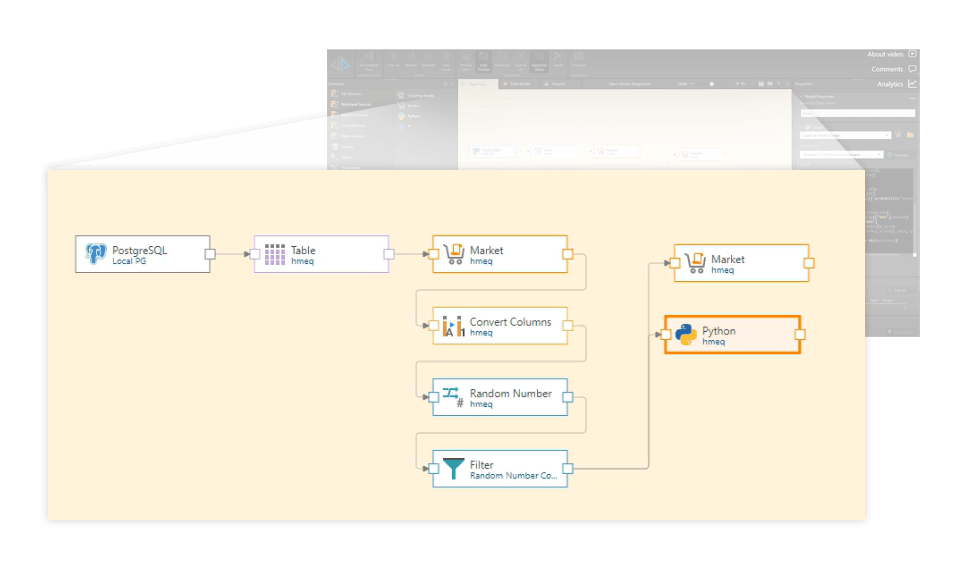
Model deployment and monitoring
Models created on Pyramid, along with their required data pipeline, can be saved, scheduled, and executed on Pyramid directly. The output of the models can be monitored on the platform to provide information on model performance over time and identify model degradation and drift. Alerts can be set to inform users when the model performance changes so the model can be retrained.
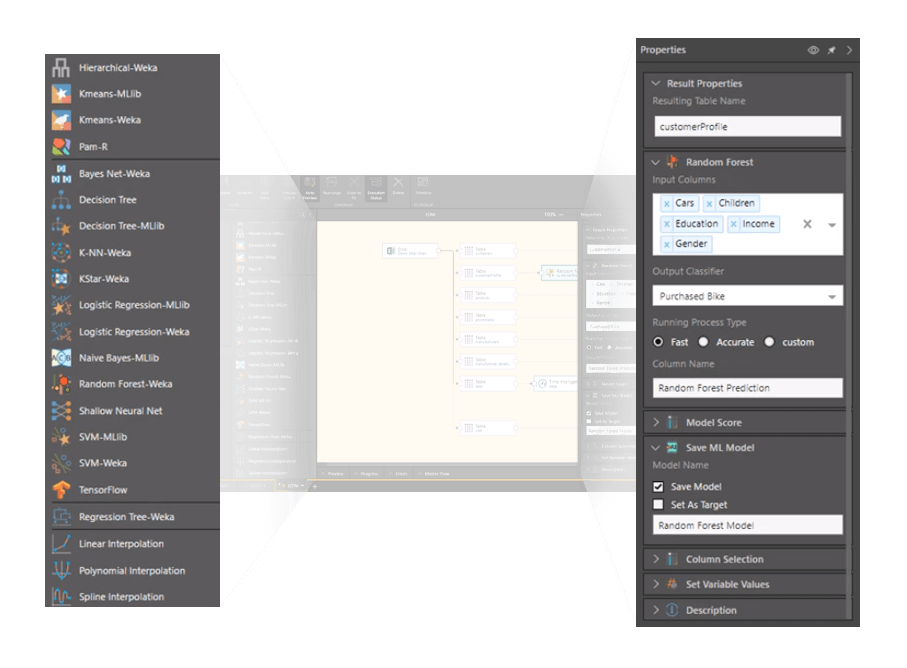
Machine learning marketplace
The Pyramid Marketplace contains pre-built ML scripts you can apply for data cleansing, data prep, transformation tasks, statistical analysis, and classic ML regression and classification tasks, such as forecasting and clustering. It features pre-built scripts for classic ML modeling tasks like sentiment analysis, market basket analysis, geospatial modeling, and more. The marketplace also includes scripts for specialized use cases like modeling stock performance, future insurance claims, infant health, and more.
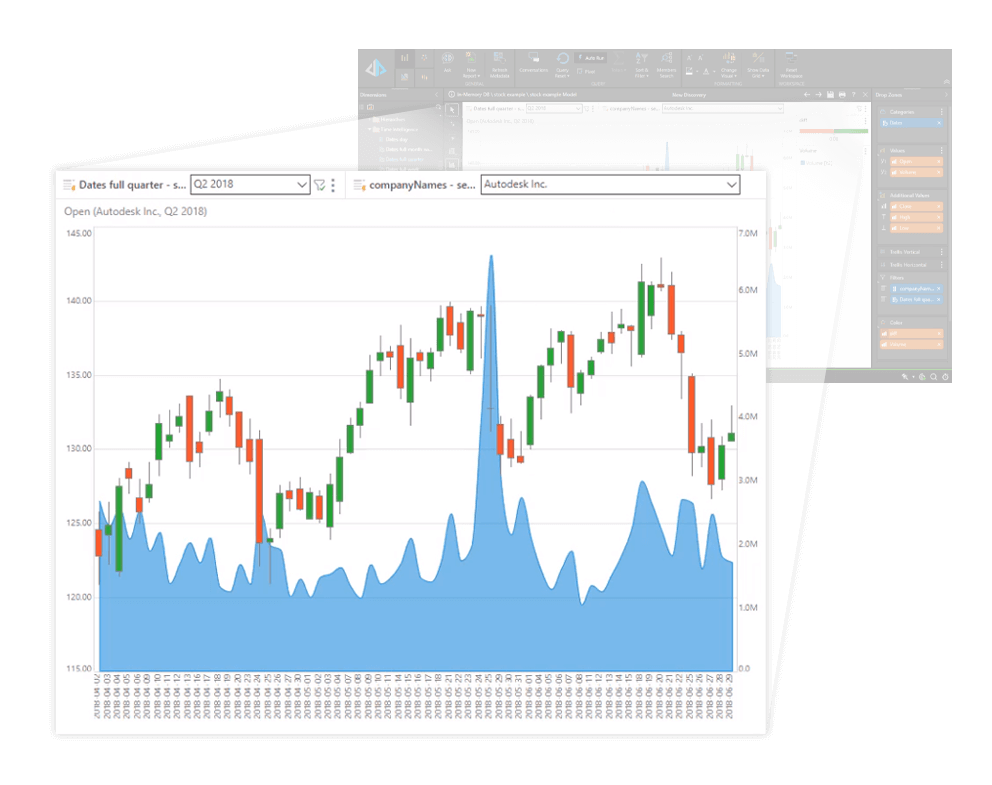
Scalable, integrated, and governed data science

Model any data
Pyramid can access data from many DSML platforms and analytical databases, including Databricks, Azure Synapse, Snowflake, AWS Redshift, Spark, blob storage, data lakes, and more.

Collaboration
Pyramid is a unified, self-service platform that is deeply collaborative, enabling data engineers, data scientists, and business analysts to collaborate throughout the ML lifecycle.
Explainable AI/ML
Users can apply analyses such as variable importance, dependence plots, LIME, SHAP, and other explainability techniques.
Self-service data science done right




Learn more about data science with Pyramid

What Does it Mean to be a Visionary?
By Omri Kohl, Co-Founder & CEO, Pyramid Analytics Revolutions sometimes appear to happen out of…

How data exploration through chat democratizes business intelligence
Business intelligence (BI) has long been regarded as the expertise of professionals who are knowledgeable…

Omri Kohl, CEO & Co-Founder of Pyramid Analytics – Interview Series
Omri Kohl is the CEO and co-founder of Pyramid Analytics. The Pyramid Decision Intelligence Platform…