
- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-



Pyramid’s multi-tiered service architecture is a perfect fit for Kubernetes-based container deployment, allowing for dynamic scaling and shrinking of distinct services to match demand.
Kubernetes is an open-source platform for managing and optimizing applications deployed typically in the cloud using containers to deliver high-scale solutions. Kubernetes facilitates elastic computing and provides an elegant framework for automatically managing memory, storage, and CPU resources, adding extra services when needed and removing excess services or resources when not.
Kubernetes and containers also offer full portability across cloud service providers and host operating systems, such as AWS and Azure. This means technology solutions can be deployed easily without re-architecting the infrastructure.
Live applications, especially in analytics, can be subject to huge spikes in resource demand. This requires scaling of the entire application to cater for the maximum workload which results in a huge redundancy of computing resources when workloads shrink. Conversely, under-resourced solutions can severely dent the uptake of a slow application and render it useless in the hands of the end-users.
The first headache is to find a solution with an architecture that allows for real scaling, such that resource demand can be met (Surprisingly, many technology solutions don’t scale regardless of design).
If scalability can be introduced into the solution architecture, it should ideally focus only on the portion of the application experiencing the increased demand when it’s needed. This optimizes the utilization of resources. This is the core principle behind a services-based architecture working in containers on Kubernetes.
Within the analytics domain specifically, many business intelligence solutions are designed as monolithic applications that run primarily as single “nodes” since they are not architected with multiple services (micro or otherwise). This design, as described above, heavily negates the benefits of containerization and Kubernetes. Often, the container options for these technologies involve running node “clones”—which only provide a small degree of elastic scaling at best.
Pyramid is designed with a multi-tier services architecture that can be scaled up or out. The services properly fit into containers that allow for individualized vertical and horizontal scaling to meet the growing and shrinking demands of an analytics deployment within a Kubernetes deployment across one or more machines, or “nodes”.
This makes Pyramid on Kubernetes a bona fide framework for delivering a true clustered, elastic computing solution for business analytics that can scale for hundreds or thousands of concurrent users.
Pyramid’s Kubernetes solution works with Docker containers and can be deployed into any standard Kubernetes cloud hosting service—including AWS, Azure, Google (GCP), and RedHat OpenShift. Further, there are specific capabilities built into Pyramid to harness the true power of Kubernetes. This primarily includes specialized functions to drive the Kubernetes management for the auto-scaling, upscaling, and downscaling of resources, ensuring optimal utilization of resources.
Unlike most business analytics solutions, Pyramid on Kubernetes can grow and shrink based on demand for analytic horsepower. This makes it a highly cost-effective solution when deployed in the cloud, where resource consumption per unit of time is the main currency.
Charne is the IT Manager at Datacorpus, a fictional software company. Datacorpus uses Pyramid to let its customers analyze their own data stored in the cloud through Datacorpus’s SaaS offering. Because there was a high number of users from each customer that can connect to their cloud solution and there are wild swings in the demand for concurrent access at any given time, Charne chose to implement a Kubernetes deployment of Pyramid on AWS using their Elastic Kubernetes Service (EKS) service.
Charne started the Kubernetes deployment by using Pyramid’s online configuration tool to design the cluster’s initial footprint. The tool is a form that calculates the best scenarios for memory and CPU allocation for each “pod” (which is the virtual service that hosts each container) based on the configuration of the Kubernetes cluster in AWS. The configuration tool generates the specification as a “YAML” file, which is the standard file structure for Kubernetes. This included settings and instructions for how to scale up each service in the cluster.
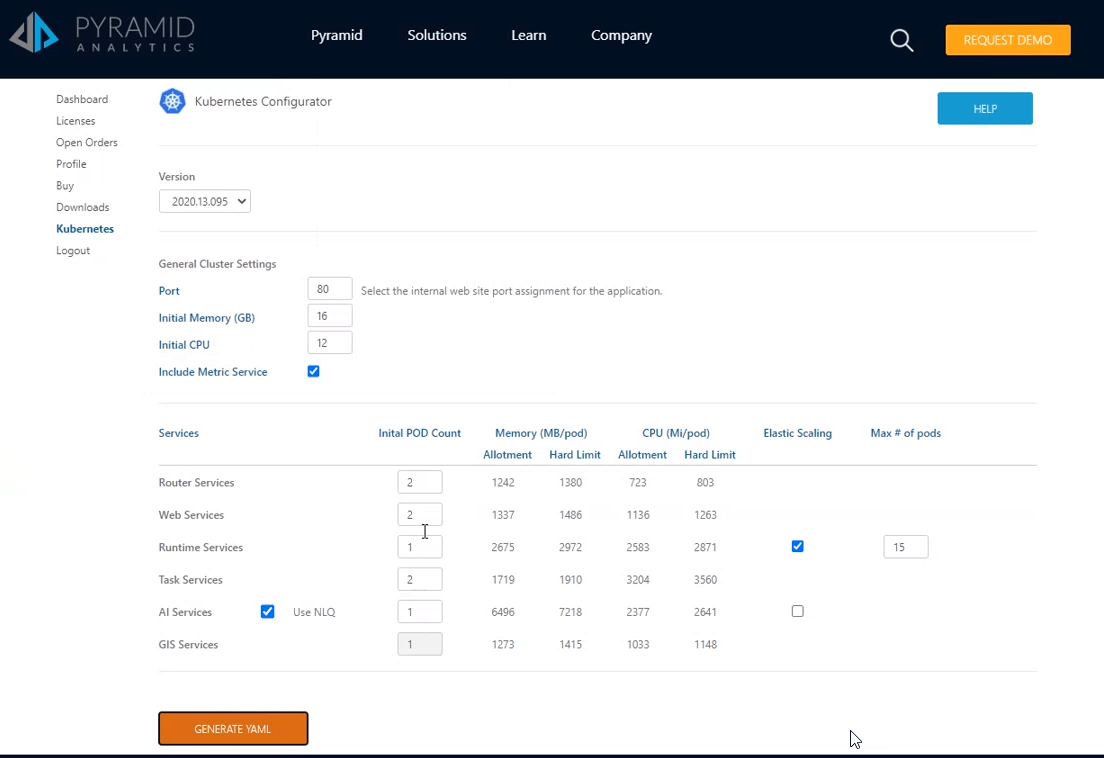
After configuring the rest of the AWS EKS setup and deploying a repository database on AWS (using Aurora RDS Postgres), Charne fired up the Pyramid cluster from the YAML file. Once launched, Charne completed the deployment by filling in all the relevant details for the implementation in the System Initialization form.
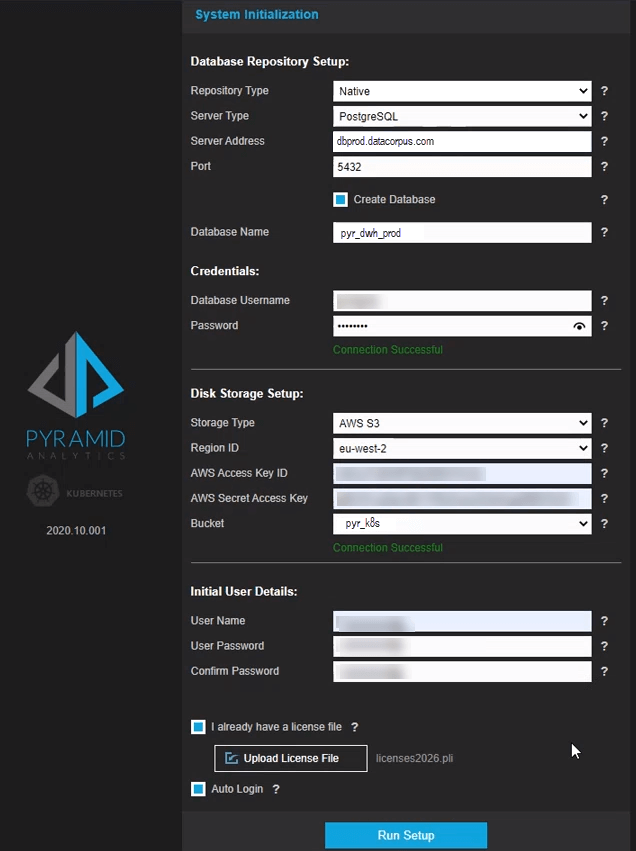
After clicking the setup button, it took the engine around five minutes to deploy Pyramid and bring it up for immediate use.
Spikes in resource demand of software applications require scaling to cater to the maximum workload, resulting in redundancy when workloads shrink—a problem acutely felt in numerous data analytic solutions and deployments.
Many BI solutions, which were architected before service-based design became prevalent, run primarily as single nodes,” negating the benefits of containerization and Kubernetes, providing a small degree of elastic scaling at best. Overall, many BI solutions don’t truly scale, and those that do cannot scale efficiently.
Pyramid’s service-oriented architecture allows distinct services to scale and shrink dynamically to match demand. Each of its services fits into containers that can be scaled horizontally and vertically to meet fluctuating demands in a Kubernetes deployment. In this way, Pyramid can comfortably handle thousands of concurrent users in the most cost-effective and resource-efficient way.
For further details about how to deploy Pyramid using Kubernetes, see our Help Guide.

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…