
- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-



Pyramid is an official member of the SAP® PartnerEdge® open ecosystem and is fully certified by SAP on SAP BW/4HANA, SAP HANA, and SAP Netweaver. The Pyramid Platform is also available on the SAP Store.
SAP HANA is an in-memory, column-oriented, relational database management system ideal for handling large datasets. Reading and querying data from SAP HANA is common in most BI toolsets—albeit with varying degrees of functionality and analytical control.
But what about building new data models (and data mashups) and “writing” them back to HANA as a target system?
Enriched data is of great value to end-users. It provides enhanced context for deeper analysis or categorization of existing data. Indeed, many machine learning processes involve adding new elements to a data set for further analysis or use. In processing such data—either cleaning it, embellishing it, or attaching new data to it—users need a place to store the processed outcome. Unfortunately, almost all BI tools (such as Power BI, Qlik, and Tableau) can only model and mash up data into their own proprietary data engines. They cannot write data back to other target systems—including SAP HANA.
While there are scenarios where this is not required, enterprises often prefer to have all data models hosted in the same enterprise technology stack rather than in siloed peripheral tools. This promotes reusability and data governance, and it allows the data assets of the enterprise to be secured and monitored.
Pyramid provides a visual, intuitive front-end tool where users can create their own data model by dragging and dropping their data sources onto a canvas. They can then perform both simple and complex data manipulations, machine learning, and AI functions by using ready-built functions, by building complex functions with point-and-click simplicity, or alternatively using pre-existing R or Python code.
The big difference is that Pyramid can use HANA as a data target where the resultant data set may be stored when the data flow process finishes. In fact, Pyramid may be one of the simplest ways to build or adjust a HANA database!
Angie is the CIO of Cornerstone Bank, an international bank specializing in personal loans. Cornerstone has an SAP HANA database and is looking for a BI system that will implement the specialized Python scripts, machine learning, and other scripts that are used to classify risk and market profiles associated with each applicant. After running a proof of concept (POC) with several vendors, it has become apparent that results from the machine-learning processes must be written back to the original SAP HANA data source. Without this functionality, data would have to be loaded onto another in-memory database, making the SAP HANA database partially redundant. In addition, unless this calculated data is materialized in the database, it must either be recalculated every time it is required (a massive, time-consuming task that doesn’t work).
Angie’s team decides to use Pyramid because it can process data from HANA, run the machine learning logic in Python, and then store the results back into HANA for analysis and reporting—all via the business user-friendly tools.
In the diagram below, Angie has used Pyramid’s self-service data modeling module. She has created a model where the SAP HANA database is accessed as a source. Various SAP HANA tables are selected, data is mashed together with an Excel source, a Python machine learning script is applied, and most importantly, the resultant data sets—using all the complex machine learning scripts—are stored on SAP HANA.
The Python script is used to predict the loan status for the next month. Existing data fields are used as inputs into the Python script detailing loan amount, interest rate, previous defaults, net monthly income, et cetera, producing a “Predict_Success” column where a value of 0 predicts a successful collection of the monthly loan repayment and a value of 1 predicts an unsuccessful collection.
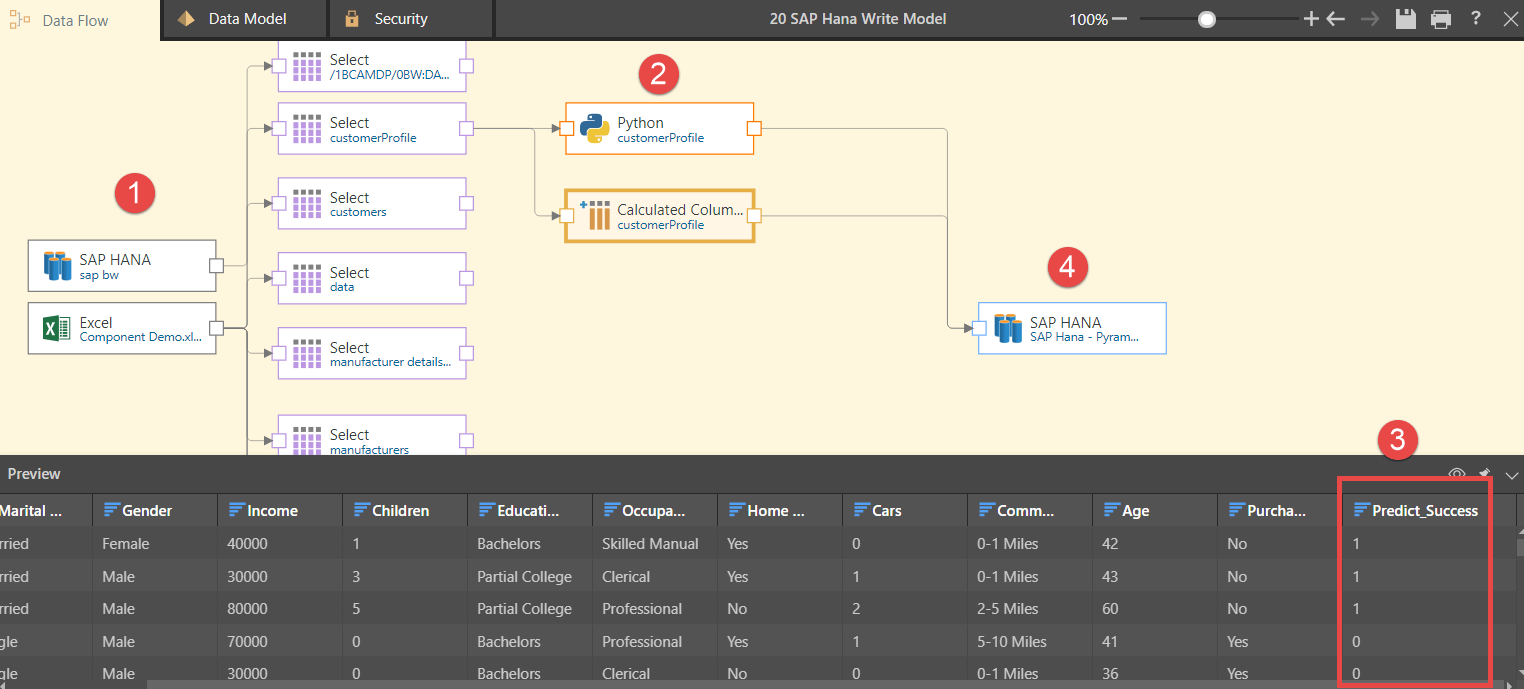
Using Pyramid, Angie runs the model and processes 10 million records in 5 minutes. With the resultant data now immediately available in SAP HANA, all subsequent reports can be run without recalculating and reloading them into a third-party database. Using Pyramid’s powerful scheduling tool, the model has been scheduled to run every Monday morning at 3:00 a.m. The availability of this feature has made Angie’s job much easier. She can now leverage the organization’s large SAP HANA investment without needing to invest in a new replicated in-memory data source.
In this blog, I have discussed Pyramid’s ability to write data back into SAP HANA through a business-user-focused data ETL and modeling tool. It allows end-users to run Python scripts, machine learning code, and other data manipulations to build new data values and write the results into the SAP HANA.
In this series of blogs, I have discussed Pyramid’s unique offering to SAP BW and HANA customers. I have demonstrated how Pyramid provides powerful support for features offered by both SAP BW and HANA while at the same time enabling direct queries on the SAP BW and HANA databases—providing a mature, flexible, and feature-rich self-service toolset for SAP BW and HANA customers.
Topics in this series of blogs include:
Pyramid solves this entire problem with a complete solution that offers real self-service working directly on SAP BW and HANA. How? By delivering best-in-class functionality and performance on SAP BW without extracting or duplicating data, Pyramid preserves the full analytic power of the SAP engines, as well as the inherent security and governance.
Please explore our Pyramid + SAP Blog Series to learn how Pyramid supports our customers on SAP. Each post contains specific examples to illustrate key functionality:

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…