
- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-



One of the classical requirements in query design is returning a result set that multiplies out the lowest level of one dimension by the lowest level on another dimension before trying to ascertain a filtered list of those dimensional combinations.
For example, let’s assume you want the customer hierarchy and product hierarchy on the rows of a query, with various measures on the column. From the Cartesian multiplication of customers times the products, you then want the top 20 combinations for a given measure, say Quantity. In other words the top 20 customer-product scenarios.
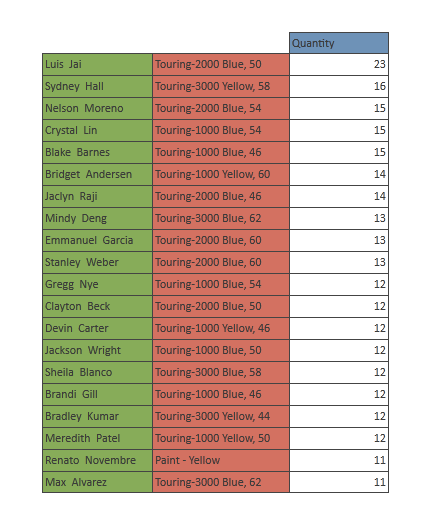
The problem here is that the top 20 filter produces a short list of results, but requires an enormous amount of cube processing that can run into the billions of calculations before you can find your top 20 items.
For example, let’s assume we have 100,000 customers and 500 products, the cube needs to crank 50,000,000 calculations (100,000 x 500) before being able to determine which of those rank as the highest 20 for a given measure.
While this may be legitimate to follow this approach in some databases, it’s typically not an efficient calculation since not every customer bought every product. In fact, most customers probably bought a few products at most. As a quick approximation, if every customer only bought 1 product, there would only be 100,000 rows in the REAL result set which is a far cry from the 50,000,000 rows needed in our simple example above. This is a typical problem found in SPARSE cubes.
Its also a growing problem with the newer ‘Big Data’ queries, where more and more people are attempting to crank mega cross join queries across multiple dimensions.
[NOTE: A similar problem can exist in SQL queries on a relational database, where it is far more efficient to filter a fact table using the first dimensional table and then crossing that with the second dimensional table join.]
Luckily, Analysis Services has 2 nifty function to address this problem: NONEMPTY and EXISTS. They are similar, but serve different purposes.
Both provide a way to filter sets in an MDX statement by eliminating all combinations of cells that are inherently empty. Applying these functions on the Cartesian set of customer times product will reduce the number of cells to calculate from 50,000,000 to 100,000 in our example above.
[NOTE: These functions are not to be confused with the “NON EMPTY” clause placed on the columns or rows axis in a typical select statement. This only eliminates entirely empty rows or columns AFTER the set has been resolved for that particular axis.]
To achieve the dramatic performance boost, users need to know when and how to implement the NONEMPTY or EXISTS function in their MDX queries. Alternatively, users can use the NONEMPTY switch in their BI tools. Unfortunately, we know of only one current MDX tool in the market today that properly enacts this functionality – Data Discovery from Pyramid Analytics. In Data Discovery, users can simply click the optimization buttons in the Query Ribbon to apply the functionality to their queries – and the resulting performance boost is dramatic.

By setting up the Cartesian query on Pyramid’s demo cube (which is based on Adventure Works) using the customer (360,000 elements) and product hierarchies on the rows (500 elements), we ran a top 20 using the Quantity measure. By clicking on the optimization buttons, the Data Discovery MDX engine explicitly applied the NONEMPTY functions and reduced the query from 10 minutes down to less than 2 seconds!
Excel 2013 can achieve a similar outcome in standard circumstances, but instead uses a hodge-podge of MDX functions inside a sub-query formation rather than use these standard functions (a super messy approach in my opinion!). It is a somewhat problematic approach if more advanced query constructs are utilized – say through more complex MDX scripts in the cube design or if you attempt to use the custom calculations and sets in Excel itself.
Users should also carefully evaluate other MDX tools to see if they allow for this functionality. Many BI client applications for consuming Analysis Services, like Tableau and Cognos, do not enable this functionality and can severely impact your organization’s analytic needs when cranking bigger, more complex analyses (and who just wants ‘simple’ these days?).
The following MDX highlights the optimization. It’s based on a cleansed version of the optimized MDX produced by Pyramid’s Data Discovery.
Most applications (or people) will write the TopCount filter statement (bold below) as the filtered list of the cross join of customers and products (highlighted in blue in separate named sets). When cranked, the filter FIRST has to complete the multiplication of these two hierarchies (50m calculations!) before ascertaining the top 20. By inserting the NONEMPTY filter (highlighted in red below) around the cross join, BEFORE running the TopCount filter, we are able to remove the empty/null combinations and only evaluate those with actual values in the filter – reducing the calculation load down by several orders of magnitude.
WITHSET [axisfinal-0] as { [Measures].[Quantity] }
SET [finalhier-Set-1-0] as HIERARCHIZE( [Customer].[Customer].[All].children )
SET [finalhier-Set-1-1] as HIERARCHIZE( [Product].[Product].[All].children)
SET [axisfinal-1] as
TopCount(
NONEMPTY( { [finalhier-Set-1-0] * [finalhier-Set-1-1] } )
, 20 , ([Measures].[Quantity]) )
SELECT
NON EMPTY { [axisfinal-0] } ON COLUMNS,
NON EMPTY { [axisfinal-1] } ON ROWS
FROM [Pyramid Sales Demo]
The last word is on the difference between the 2 functions.
EXISTS is designed to run on the fact values stored in the cube’s partitions, while NONEMPTY is designed to run within the context of the cube itself.
So one benefit is that NONEMPTY can use calculated members as the basis for optimization, while the EXISTS function cannot. But more explicitly, as of SQL Analysis Services 2005, cubes can preserve NULL values read in from the original fact tables. The EXISTS function, running at the fact table level, will give combinations of items (customers and products in our example) even if their associated measure (Quantity) is null. While NONEMPTY will exclude those from the result set (since they are ‘empty’ at the cube level).
You can read more about it from MDX guru Mosha Pasumansky.
What was the largest MDX query you ever ran – was it easy or difficult to get the data insights you needed?

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…