
- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-



It’s very common for organizations to possess large datasets that only require periodic updates on a smaller subset of the data. In other words, only new data or data that has been recently updated needs to be refreshed.
Incremental data refreshing enables partial loading of a dataset. To achieve this, BI tools must be able to run custom SQL scripts to dynamically select reduced datasets while injecting a pre-loaded variable to further filter the query. Pyramid’s incremental data refreshing—with built-in variable control and SQL injection and execution—facilitates quicker processing and reduced resource consumption for common, but complex, business scenarios.
Massive data reloads are time-consuming, require exclusive use of processors and memory, and can delay the delivery of scheduled reports. Most BI tools do not provide a comprehensive set of ETL tools for data pipeline processing, let alone support custom SQL queries for handling true incremental scenarios.
Some BI tools rely on specific date-type fields or can only incrementally refresh certain columns. By not allowing refreshing based on more complex definitions, they compel users to perform unnecessary tasks to refresh incrementally or, even worse, revert to full data refreshes.
Pyramid’s modeling tool provides an intuitive graphical interface with powerful manipulation tools to provide customized data pipeline processing, enabling extended functionality for the refresh process. User-defined variables can be easily defined, initialized, and automatically updated in the Model application. Customizable database queries can be created using SQL, Python, or R scripts using injected variables, allowing for a powerful and flexible reduction of the dataset used as the “source” for the incremental refresh. Any data type can be used to define the column to be incrementally loaded. In addition, Pyramid provides tools to preview the results of an incremental refresh and monitor its progress.
Lee is a BI Analyst for ACE Industries, a computer equipment reseller. ACE uses Pyramid to analyze its Oracle database, which holds a five-year transactional data history with over 200 million rows. 150,000 rows of new data are loaded into the data warehouse daily. Lee has set up the incremental data refresh to avoid reloading all 200 million rows daily.
Lee first sets up a data model sourced from her Oracle production server using a custom SQL query. She sets the Oracle warehouse server as her target. She then sets up “MaxID”—a variable that stores the identification of the last record updated in the database.
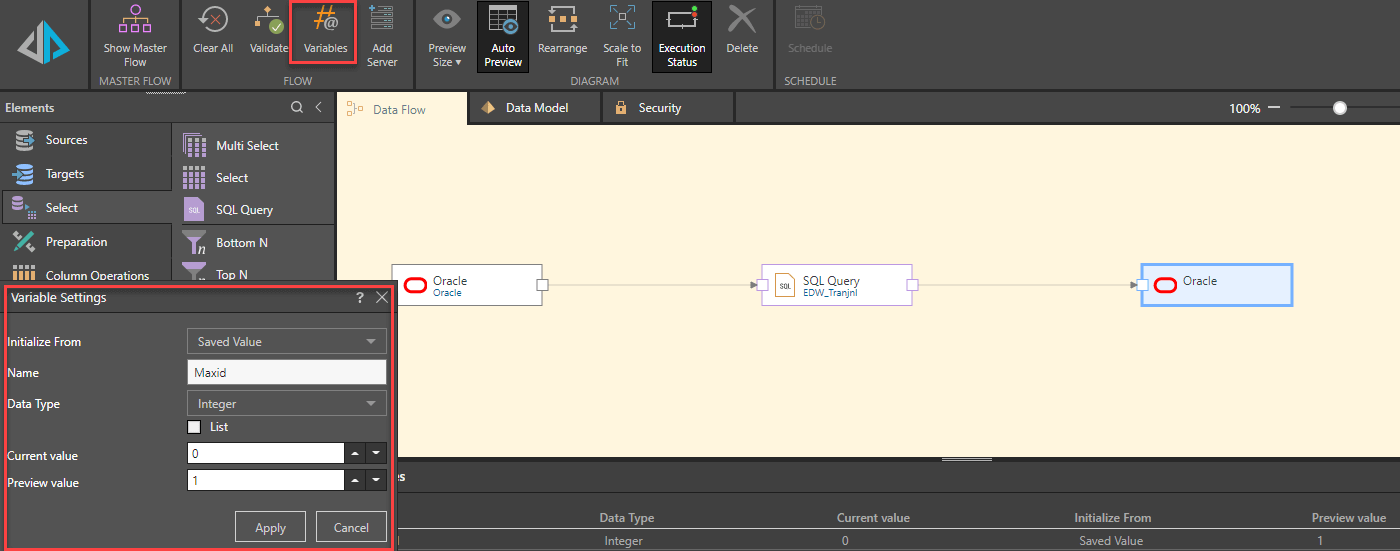
Lee then adjusts her custom query to inject the variable value (“@MaxID”) at runtime, selecting records greater than the variable value, thereby ensuring that only new records will be selected. Lee can also modify her existing SQL script as required to fine-tune the selection criteria, without requiring any other changes.

And finally, Lee modifies the writing type from “Replace” to “Append” for the target table in the data warehouse so the refresh will only append new records.

Lee has an additional business requirement: the pricing for a memory component in their product changes daily, and she has to update the vendor pricing table for a specific vendor on a separate data model. The third-party vendor pricing application does not apply a date timestamp (unfortunately, still a real-world problem), so Lee must run a customized SQL query to pick up the last record and update the target database. Without requiring a crude workaround—or total refresh to update a single record—Lee can simply apply her customized SQL to her incremental refresh and avoid massive unnecessary processing.
SELECT * FROM [vendorprice] Where [id] = (SELECT max[id] FROM [vendorprice] Where vendor_id = “FPZ001” and prod_id = “mem029”)
ACE also has a legacy sales system that defies accepted audit practices. The system allows historical records to be modified, without changing the date timestamp. To avoid a daily replace of the entire transaction table, Lee uses Pyramid’s master data flow features to first delete and then insert only records that have been modified. In my next blog on master data flows in Pyramid I will demonstrate how to drastically reduce the processing time for the database load using a “delete-and-insert” strategy.
Large datasets that feature only small subsets of new data should not require unnecessary processing. After all, it doesn’t make sense to replace all records every day, when only a small portion of the data needs to be refreshed. Most third-party BI tools have a light ETL offering at best and a few can only perform incremental refreshes on tables with date-type fields or specific columns, drastically limiting the capability of incremental refreshes.
Pyramid allows users to use database queries to define the subset of data that requires incremental refreshing. User-defined variables can be applied to tables, calculated columns, filter nodes, Python, R, or SQL scripts to assist in the incremental refreshing. In addition, Pyramid provides tools to preview the results of an incremental refresh and monitor its progress. In short, Pyramid’s incremental data refreshing facilitates quicker processing, encourages broader application of the incremental data refreshing process, and reduces resource consumption.

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…