- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-



Data modeling is now central to all business analytic processes as companies embrace the “Decision Intelligence” paradigm. Delivering advanced data modeling options in a self-service framework is challenging – and maintaining the workflows created in the process can complicate things further.
Pyramid provides enhanced no-code tools to allow users to maintain better-existing data flows and ETL logic in its data modeling toolset – making the process of creating and maintaining such complex flows easy, accessible, and fully self-service-centric.
After having built data preparation pipelines to cleanse, transform and enrich data, model designers often need to adjust them at a subsequent time. For example, when migrating from a development to a production environment, the data sources or targets need to be adjusted; after a change in the data warehouse, tables are removed, and columns are renamed.
Some of the changes may involve the changing of input tables, while all other logic and manipulations remain intact. Alternatively, designers may want to adjust a node in the data pipeline and then walk through the downstream adjustments required.
Instead of creating a sequence of events that disrupts the pipeline and is rendered useless, Pyramid identifies the adjustments and provides a specialized mapping wizard to walk the designer through the process of rewiring the logic to the changes. Ultimately this maintains all subsequent logic without requiring a full do-over. The column mapping wizards also let designers correct any variances and issues WITHOUT CODE, sparing the designer the burden of having to recreate all the logic and data manipulations in the model.
This model has been created in a development environment with a masking process, custom Python code, and a Distinct process used for manipulating and enriching the source data.
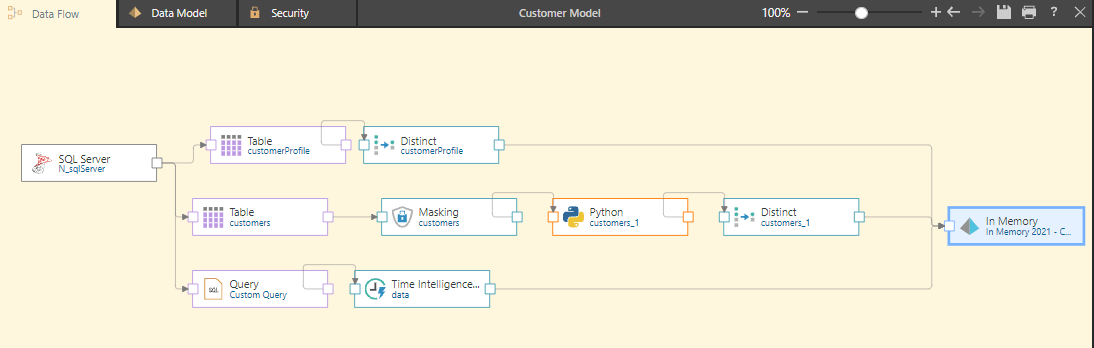
In moving the environment from testing to production, the server and subsequent table names have changed in the production environment. The different names cause an error for the table names.
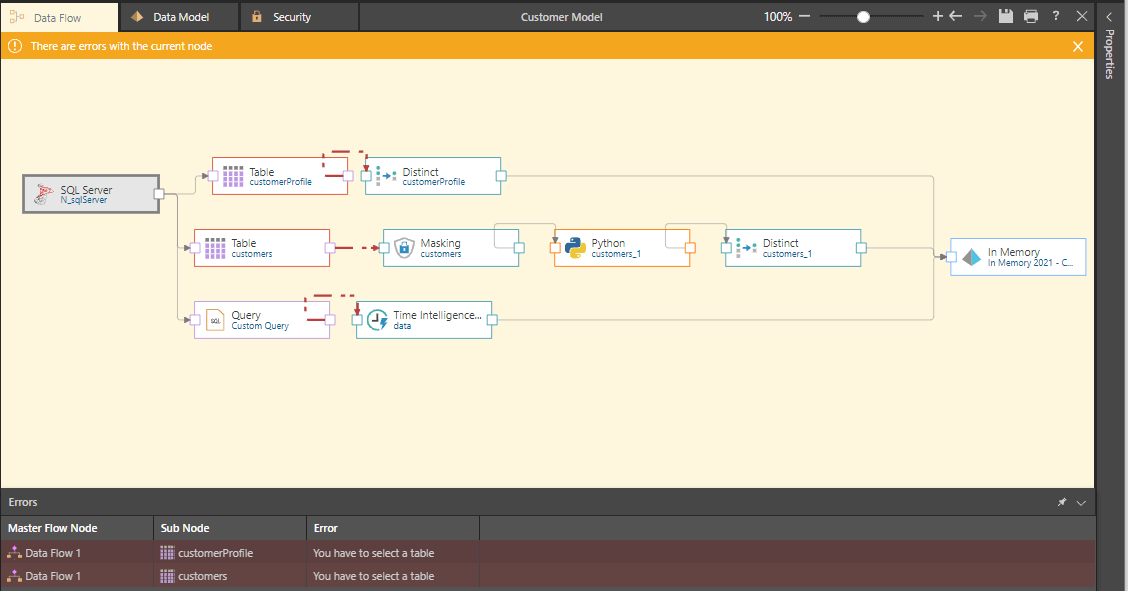
By simply clicking on the error and selecting the correct table name, the model “validates” correctly. All pre-existing logic downstream in the pipeline remains valid, so the model designer does not have to recreate any of the logic.
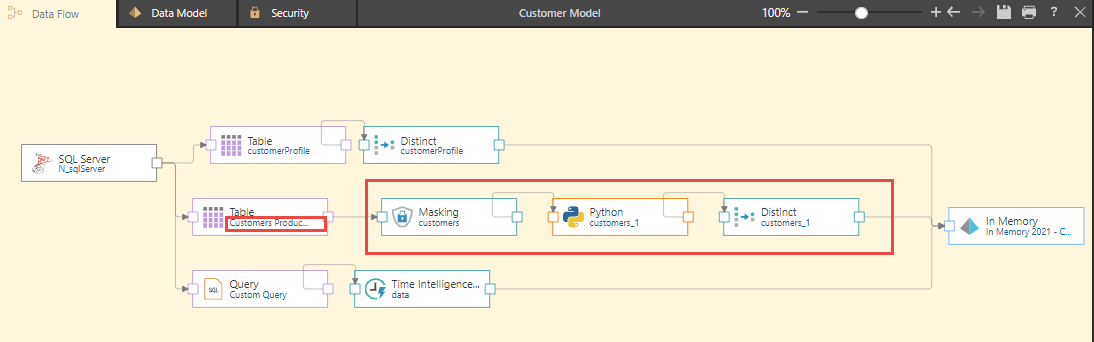
If an error exists on a column due to a mismatch or different naming of a column, the joins are changed to dotted read links. By clicking on the link between the table and the subsequent process, a column mapping panel is opened where the model designer can rectify the error. Tools are available to either individually or heuristically map or unmap source to destination columns. After clicking on the apply button and saving the model, the new model mapped to the current data source is fully operational without having to recreate all logic from scratch.
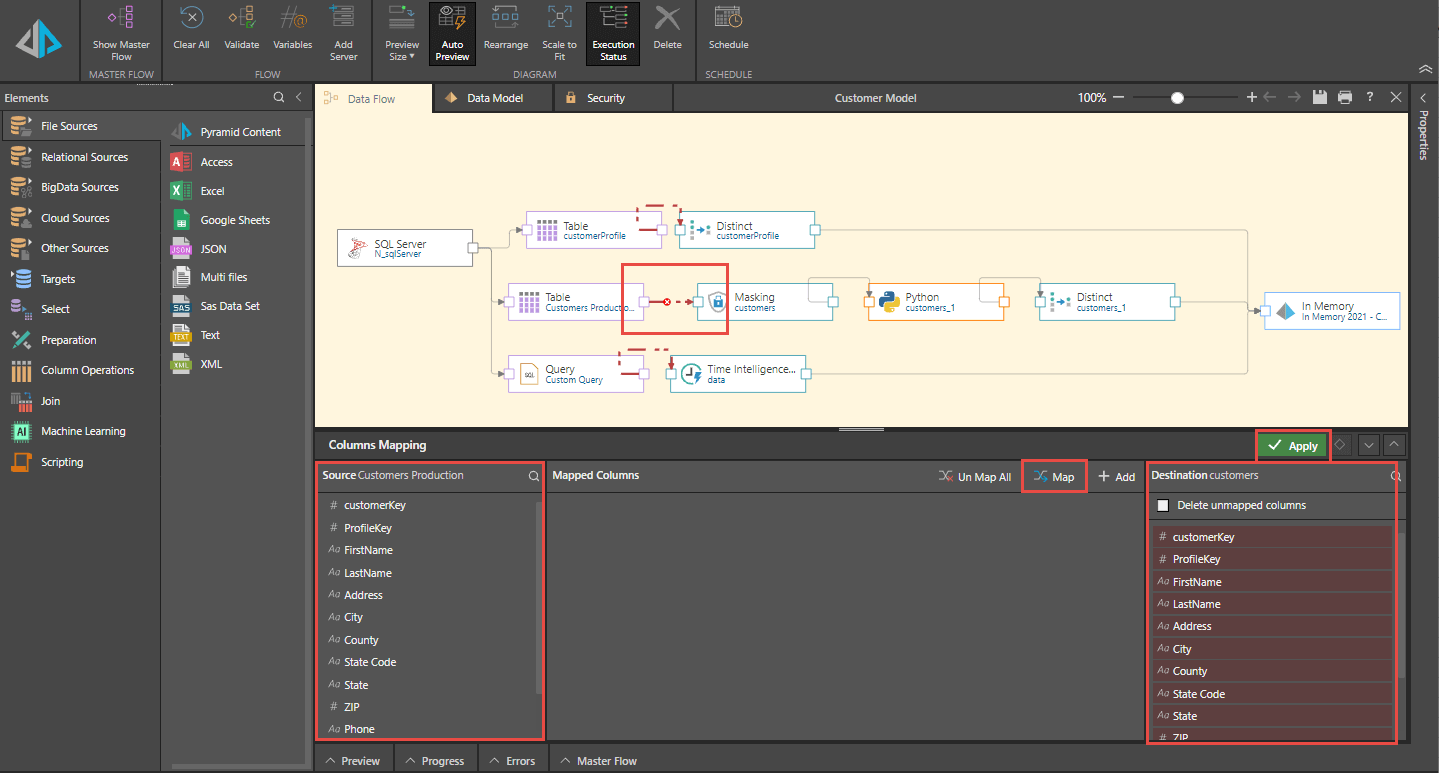
Model designers often perform simple changes like changing input tables or adjusting a node in the data pipeline. Instead of disrupting the pipeline and rendering it useless, Pyramid provides a new code-free mapping wizard allowing the designer to rewire the logic to the new changes, sparing the designer the burden of having to recreate all the logic and data manipulations in the model. Saving time and money!

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…