
- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-



A business decision supply chain contains a sequence of processes through which data owners (producers) can transform raw data into trusted and actionable business information for themselves and other users (consumers) to help make better business decisions. When integrated into a modern, cloud-ready, self-service analytics platform, users across the organization can collaborate with data to experience transformative changes.
Imagine data stewards, data managers, BI developers, and even the chief data officer at Company X—a fictional enterprise retailer—swamped as they manage the constant stream of requests for data.
Individuals across the business are hungry for it, and the requests come from all across the organization: from the COO, divisional managers, assembly line foreman, and all other employees who’ve discovered a burning need for data.
Not only are the requests piling up, but they’re also all distinct. Some people simply want the data: they’re fully equipped to work with it themselves. Others just need a formatted report sent regularly for review.
The data team struggles to fulfill everyone’s requests in a timely manner. Turning the screws, the security and IT teams at Company X struggle to ensure governance and compliance rules are followed.
With all the complications and waiting, countless users turn to old data and begin exchanging Excel spreadsheets via email instead.
How can the various data producers at Company X manage all their own sources successfully, and still respond to their data consumers’ individual demands?
A vertically integrated enterprise analytics platform makes it possible for data producers to support data consumers’ decisions in a process we call the Business Decision Supply Chain.
In an earlier post, I introduced the concept of the Business Decision Supply Chain, a sequence of processes by which analytics producers turn raw data into trusted and actionable business information for analytics consumers. In a second post, I began to unpack the different parts of the supply chain, highlighting the four responsibilities of the modern analytics producers and data consumers.
In this third post, I’ll examine the data producers side of the supply chain in even greater detail.
The ideal analytics decision lifecycle follows a business decision supply chain pattern where analytics producers turn raw data into trusted and actionable business information and then distribute it to analytics consumers through purpose-built channels that best serve their needs and overall decision-making.
Let’s explore how this is made possible through four key processes that constitute the analytics producer’s side of the Business Decision Supply Chain: acquire, enrich, assemble, and deliver. We’ll identify some of the common challenges and shortcomings among modern enterprises today and then highlight opportunities to improve these processes by embracing a new data analytics paradigm.
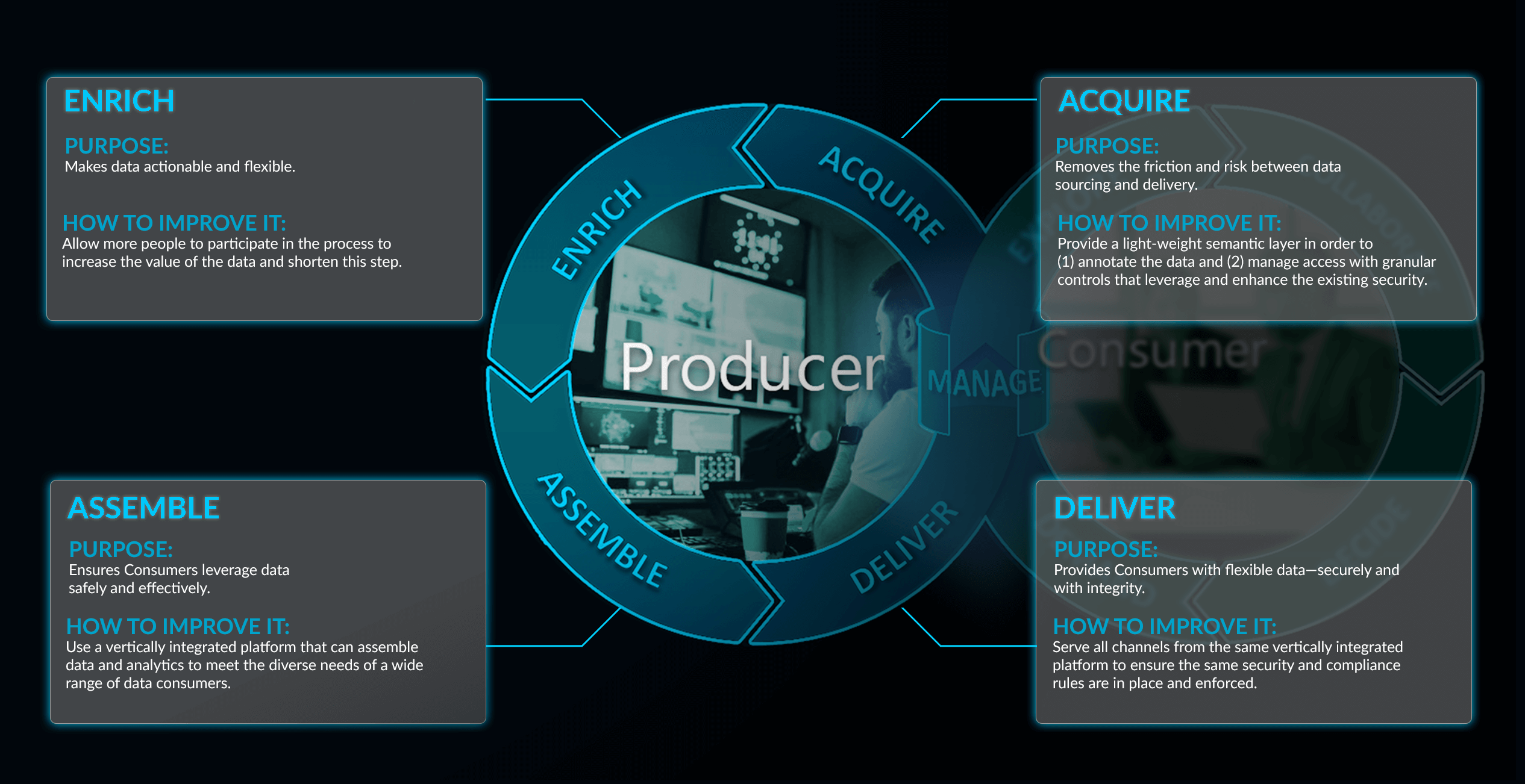
This is the beginning—and for many organizations the most difficult part—of the supply chain. Data typically resides in multiple data management systems. Data stewards and managers need an easy way to make the data available no matter where it resides. In addition, they need to provide some guidance about the data’s significance, how it should be used, and how often it is refreshed.
The approach for most is to export to a file, often Excel. Others implement complicated ETL or data integration platforms. But in the end, both introduce complexity. And both do not really make the data easily available to a broader audience.
A vertically integrated data and analytics platform can fulfill this requirement by first providing a direct access channel to all the data sources. This removes the need to spend months (or years) trying to move all relevant data to a single place. It also minimizes the need to duplicate data and pay for the infrastructure required to house that data. In some cases, moving data from its system of record to a more analytics-friendly store is unavoidable. But in many cases, data can be queried directly from where it is.
The key is to provide a light-weight semantic layer. This allows a producer to annotate the data, provide information on what the data is and how to use it, and to manage access through granular controls that leverage and enhance the existing security on the data store itself. This layer should also provide the ability to access the data without the need to write code or use specialized tools. In this way, data stewards can easily and securely make data available for all types of users and needs.
Enrichment is the process in which the value of the data is increased by adding more depth—through calculations, outside reference data, or Machine Learning scripts. Traditional enrichment tools can be prohibitively expensive and difficult to learn. What’s more, the enrichment process can be impractical with large data sets, or inaccessible when producers don’t have a practical means of sharing unique insights with consumers (e.g., valuable predictions that leverage relevant data but lack a practical means of delivery).
The key to increasing the value and effectiveness of the enrichment step is to allow more people to participate in the process. This step is typically the bastion of the data scientist or BI developer—that small group of technically skilled people whose expertise is in data enrichment itself. The challenge is that these people aren’t always familiar with the underlying data itself. In other words, they may be adept technically, but aren’t necessarily familiar with the business value of the data. By giving those who know the data the means to enrich it, this not only improves its value but shortens this step in the supply chain. The platform must provide an interface that is usable to a broader audience but doesn’t compromise on the sophistication of the capability.
This stage transforms data into a more consumable format: visualizations, KPIs, natural language generation, infographics, and other formats that support exploration and collaboration by traditional analytics consumers, including business analysts, financial analysts, first-line managers, and others. The challenge comes because there are so many kinds of consumers, each with different needs. In order to address these different needs, organizations often deploy different tools. The net effect is difficulty in driving adoption—and consumers fall back to offline data in Excel and collaborating by sending spreadsheets through email. In other words, data and analytics chaos and huge security and compliance risks.
With the right vertically integrated platform, data and analytics can be assembled to meet the diverse needs of a wide range of data consumers. Good assembly means looking past dashboards with filters, which force users to work and analyze a certain way, to provide more sophisticated ways of delivering analytics. In addition to the traditional online dashboard experience, the right platform will offer consumers a more encapsulated experience. Baseline analysis will be automatically generated and provided to them. Rather than interpret complicated visualizations, consumers will use natural language and have a conversation with their data to explore and uncover insights.
Delivery represents the last mile of the producer side of the supply chain, but in some cases, it’s the most difficult. Consumers have become fickler and more demanding in their analytics needs. They represent diverse skill sets and levels of technical savvy. They want what they want when they want it, and in the way they want it. This can mean a log-in experience, a report delivery experience, a mobile experience, or an embedded experience. Rather than having to go to the analytics, consumers want the right analytics to come to them at the right time.
Deploying a separate tool to support all the above-described channels is costly and time-consuming. It also means having to potentially create and maintain multiple copies of the same data—or mostly the same data with subtle differences. Serving all these channels from the same vertically integrated platform removes this complication and ensures that the same security and compliance rules are in place and enforced regardless of the channel through which the analytics are delivered. Once assembled, it should be very simple to deploy analytics anywhere based on the needs of the consumer and evolve as those needs evolve.
When your data analytics supports your entire business decision supply chain—and all the successful communication, collaboration, and self-service that entails—your company maximizes the value of its data without sacrificing security or governance. At Company X, this is applied to individual data consumers as well as senior executives seeking to inform strategic company decisions. The immediacy of that information can drive faster and more informed decision-making at both levels of the organization. Now, even as consumers’ needs evolve, the experience and insights each of their analytics facilitates can be adjusted to meet those demands.
Pyramid Analytics is a completely server-based solution, designed to meet the needs of modern business decision supply chains at enterprise companies. Contact us today and discover how your users—both producers and consumers—can get the most from your analytics investment, driving real business value in the process.
This post is a part of our five-part series on the Business Decision Supply Chain. Revisit any of the other posts to learn more:
BI Trends
2023 was the year of AI in almost every industry. However, when it comes to…

Thought Leadership
Introducing Data Shark Podcast, with Omri Kohl Pyramid Analytics’ CEO, Omri Kohl, is a busy…

Thought Leadership
Organizations that use analytics often experience a gap between analytics results—the products of data preparation,…

Events
Disclaimer: This article is the opinion of Pyramid Analytics and does not constitute an endorsement…

Events
Disclaimer: This article is the opinion of Pyramid Analytics and does not constitute an endorsement…

Thought Leadership
Has “augmented analytics” reached peak hype? It certainly feels that way. Countless software vendors in…

Thought Leadership
A conversation with the business analytics expert and professor, Gauthier Vasseur “Data is not important.…

Mythbusting
Data replication is the process of storing the same data in multiple spots to improve…

Mythbusting
Does it still make sense to take a department-by-department approach to analytics? Can you invest…